
课程介绍
大数据硬核技能进阶 Spark3实战智能物业运营系统视频教程,由it资源网整理发布。本课程将结合生产级项目,一栈式点亮:数据收集(DataX)、数据湖(Iceberg)、数据分析(Spark)、智能调度(DS)、数据服务(DBApi)、AI大模型(ChatGPT)、可视化(Davinci)等离线处理核心技能及生态体系,带你打通硬核技能,拓宽上升通道。
相关推荐
极客时间 – 大数据训练营
Flink 从0到1实战实时风控系统
9大业务场景实战Hadoop+Flink,完成大数据能力进修
Spark离线处理核心技能、端到端一栈式全流程方案设计技能、生产环境故障与性能调优核心技能、源码研读+二次开发技能

从入门到进阶,构建完整的 Spark 离线处理+生态技术体系
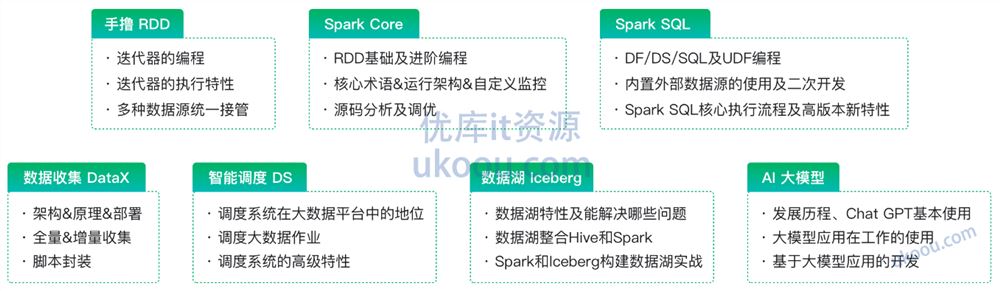
资源目录
.
1-大厂技术首选高薪必备:揭开Spark神秘面纱/
[ 21M] 1-1 每位大数据开发者都需要了解的硬核技能
[2.1M] 1-2 本章概览
[ 22M] 1-3 Spark产生背景
[ 30M] 1-4 Spark是什么
[ 21M] 1-5 [重要]Spark能为我们带来什么
[ 11M] 1-6 自己语言总结Spark
[ 44M] 1-7 [重要]Spark版本选择依据
[ 28M] 1-8 Spark与Hadoop多角度对比
2-工欲善其事必先利其器:大数据框架环境部署/
[2.3M] 2-1 本章概览
[3.6M] 2-2 [重要]服务器选择注意事项
[ 20M] 2-3 客户端操作注意事项
[5.9M] 2-4 服务器目录规划
[ 21M] 2-5 JDK部署
[ 10M] 2-6 Scala部署
[5.8M] 2-7 [作业]MySQL部署
[ 71M] 2-8 HDFS部署及测试
[ 37M] 2-9 YARN部署及测试
[ 63M] 2-10 Hive部署及测试
[ 49M] 2-11 Spark部署及测试
[ 60M] 2-12 [重要]基于IDEA&Maven构建本地开发环境
3-手把手撸个RDD实战:加强基础为Spark预热/
[4.0M] 3-1 本章概览
[ 17M] 3-2 快速认识Java中的Iterator
[ 63M] 3-3 自定义Java Iterator
[ 30M] 3-4 自定义Java Iterable
[ 22M] 3-5 [重要]Scala中迭代器的使用
[ 37M] 3-6 [重要]自定义迭代器读取MySQL中的数据
[ 25M] 3-7 统一上下文类封装
[ 23M] 3-8 Scala中迭代器的lazy特性
[ 52M] 3-9 [重要]自定义RDD代码封装及实现
[ 37M] 3-10 自定义RDD代码测试
4-轻松理解RDD核心本质:结合源码多维度解析/
[2.0M] 4-1 本章概览
[ 10M] 4-2 学习之前注意事项说明
[ 37M] 4-3 [重要]从源码角度理解RDD是什么
[ 20M] 4-4 [重要]从源码角度理解RDD的定义
[ 50M] 4-5 [重要]从源码角度理解RDD的五大特性
[ 38M] 4-6 RDD五大特性在源码中的体现
[ 11M] 4-7 RDD五大特性图解总结
[ 58M] 4-8 HadoopRDD源码解读
[ 15M] 4-9 [作业]JdbcRDD源码分析
5-快速步入核心编程基础:RDD转换与动作编程/
[3.7M] 5-1 本章概览
[ 53M] 5-2 Spark编程核心入口类SparkContext使用注意事项
[ 45M] 5-3 基于spark-shell脚本再谈SparkContext
[ 37M] 5-4 RDD创建方式之集合
[ 33M] 5-5 初遇并行度
[ 15M] 5-6 自定义类型数据转成RDD
[ 58M] 5-7 RDD创建方式之文件系统数据
[8.0M] 5-8 [作业]拓展读取文件系统数据
[ 55M] 5-9 RDD创建方式之MySQL中的表
[ 26M] 5-10 RDD操作概述
[ 57M] 5-11 transformation之map算子
[ 34M] 5-12 transformation之flatmap算子
[ 30M] 5-13 transformation之mapPartitions算子
[ 60M] 5-14 transformation之filter算子
[ 10M] 5-15 transformation之sample算子
[8.4M] 5-16 transformation之glom算子
[ 28M] 5-17 transformation之zip算子
[ 28M] 5-18 从一个经典的面试题掌握算子底层的实现原理
[ 37M] 5-19 transformation之mapValues算子
[ 30M] 5-20 transformation之flatMapValues算子
[9.6M] 5-21 transformation之keys&values算子
[ 14M] 5-22 transformation之keyBy算子
[ 26M] 5-23 transformation之reduceByKey算子
[ 21M] 5-24 transformation之groupByKey算子
[ 25M] 5-25 经典面试题之reduceByKey对比groupByKey
[ 32M] 5-26 transformation之groupBy算子
[ 12M] 5-27 transformation之sortBy算子
[ 16M] 5-28 transformation之sortByKey算子
[ 24M] 5-29 transformation之distinct算子
[ 56M] 5-30 transformation之cogroup算子
[ 56M] 5-31 transformation之join算子
[ 28M] 5-32 transformation之交并差算子
[ 26M] 5-33 action算子之collect
[ 20M] 5-34 action算子之foreach
[ 26M] 5-35 action算子之foreachPartition
[ 26M] 5-36 action算子之取数相关
[ 64M] 5-37 action算子之aggregate相关
[ 23M] 5-38 action算子之fold&reduce
[ 28M] 5-39 算子之countByKey&countByValue
[ 16M] 5-40 算子之查看RDD的依赖关系
[ 56M] 5-41 [拓展]Java语言开发Spark应用之map
[ 25M] 5-42 [拓展]Java语言开发Spark应用之flatMap
[6.0M] 5-43 [拓展]Java语言开发Spark应用之filter
[ 24M] 5-44 [拓展]Java语言开发Spark应用之词频统计
6-智能物业运营系统第一篇:地理位置的解析实战/
[4.9M] 6-1 本章概览
[7.9M] 6-2 明确需求
[ 23M] 6-3 架构拓展
[ 62M] 6-4 省份维度统计功能开发
[ 17M] 6-5 MySQL表及工具类准备
[ 31M] 6-6 统计结果入表
[ 12M] 6-7 统计结果入表迭代
[ 39M] 6-8 [经典面试题]Spark中的闭包
[ 33M] 6-9 [经典报错]Task not serializable-
[ 29M] 6-10 使用RDD完成普通的Join操作
[ 37M] 6-11 使用RDD完成广播变量的Join操作
[9.4M] 6-12 使用广播变量迭代ip解析功能
[ 30M] 6-13 [非常重要]使用累加器完成数据质量指标
[ 22M] 6-14 累加器在使用过程中注意的坑
[ 36M] 6-15 自定义Int类型累加器
[ 60M] 6-16 自定义复杂类型累加器
[ 46M] 6-17 可视化框架部署
[ 11M] 6-18 可视化大屏制作
[ 37M] 6-19 全流程打包到服务器上运行
[ 22M] 6-20 [扩展]高德地图API的使用
7-深入理解核心必备进阶:分区器依赖缓存策略/
[3.9M] 7-1 本章概览
[ 53M] 7-2 分区数调整算子
[ 32M] 7-3 Spark中分区器的定义
[ 45M] 7-4 自定义分区器在Spark中的使用
[ 67M] 7-5 [加强]分区数及分区器加强
[ 22M] 7-6 RDD的Lineage特性
[ 36M] 7-7 [重要]窄依赖&宽依赖的定义
[ 38M] 7-8 [重要]图解依赖及stage切分
[ 14M] 7-9 ShuffleDependency类定义的参数说明
[ 27M] 7-10 初遇Spark的缓存
[ 30M] 7-11 缓存策略的选择
[ 66M] 7-12 [重要]不同缓存策略的测试
[9.5M] 7-13 缓存清理
8-架构知其然知其所以然:术语&运行架构&on YARN/
[2.5M] 8-1 本章概览
[6.8M] 8-2 引入
[ 65M] 8-3 [重要]核心术语之一
[ 62M] 8-4 [重要]核心术语之二
[8.2M] 8-5 核心术语总结
[ 15M] 8-6 [补充]-DAG图
[ 32M] 8-7 运行架构
[9.5M] 8-8 YARN重要知识点
[ 33M] 8-9 Spark on YARN概述
[ 49M] 8-10 client模式测试
[ 34M] 8-11 cluster模式测试
[ 17M] 8-12 [重要]两种模式的区别-
[5.1M] 8-13 [补充]多节点进程的分布
9-智能物业运营系统第二篇:大数据应用监控及告警/
[认准一手完整 www.ukoou.com]
[2.8M] 9-1 本章概览
[ 17M] 9-2 监控在工作中的重要性
[ 13M] 9-3 Spark应用程序执行完毕后存在的问题
[ 65M] 9-4 为什么要引入历史服务
[ 46M] 9-5 HistoryServer部署
[ 22M] 9-6 HistoryServer重要参数讲解
[ 45M] 9-7 学习如何阅读源码
[ 35M] 9-8 如何基于HistoryServer打造自己的监控系统
[ 36M] 9-9 [重要]打造自己的Spark应用程序监控设计
[ 44M] 9-10 邮件发送工具类开发
[ 56M] 9-11 [重要]实现自定义监控监听器
[ 35M] 9-12 [重要]是否告警开关控制
[5.4M] 9-13 [拓展]其他监控系统
10-高手成长路线之学调优:RDD各种姿势的调优/
[3.4M] 10-1 本章概览
[ 16M] 10-2 调优展开的维度
[ 58M] 10-3 调优之序列化
[ 16M] 10-4 调优之算子的合理选择01
[7.5M] 10-5 调优之算子的合理选择02
[ 22M] 10-6 调优之算子的合理选择03
[ 41M] 10-7 调优之算子的合理选择04
[ 13M] 10-8 调优之算子的合理选择05
[ 49M] 10-9 调优之数据本地性
[ 12M] 10-10 case在spark-shell中的使用
[ 19M] 10-11 dirname和if在spark-shell中的使用
[ 28M] 10-12 spark相关脚本的依赖关系
[ 27M] 10-13 Spark作业的资源影响问题
[ 72M] 10-14 Spark内存管理宏观认知
[ 38M] 10-15 Spark内存管理之SMM
[ 45M] 10-16 Spark内存管理之UMM
[ 33M] 10-17 Spark内存管理之UMM扩展
11-智能物业运营系统第三篇:业务数据采集及累计问题/
@it资源网ukoou.com
[4.6M] 11-1 本章概览
[7.3M] 11-2 数据采集框架介绍
[ 23M] 11-3 DataX是什么
[ 19M] 11-4 DataX工作原理
[ 17M] 11-5 DataX运行流程
[ 28M] 11-6 DataX快速入门
[ 85M] 11-7 使用DataX完成MySQL2HDFS的操作
[ 29M] 11-8 使用DataX完成MySQL2HDFS的操作续
[ 18M] 11-9 使用DataX完成MySQL2HDFS分区的操作
[ 12M] 11-10 数据关联Hive表
[ 22M] 11-11 实战之需求描述
[ 12M] 11-12 实战之数据流向分析
[ 57M] 11-13 实战之加载数据到Hive表
[ 73M] 11-14 实战之Hive自连接方式分拆实现
[ 34M] 11-15 实战之Hive自连接方式完整实现及优化
[ 15M] 11-16 实战之Hive窗口函数实现
[ 57M] 11-17 实战之使用RDD算子实现
12-最热门的AI大模型入门:ChatGPT为工作插上翅膀/
[2.9M] 12-1 本章概览
[ 16M] 12-2 认识OpenAI这家公司
[8.7M] 12-3 语言模型&大语言模型的趋势
[ 29M] 12-4 NLP发展历程
[ 12M] 12-5 国内大模型介绍
[ 24M] 12-6 [重要]Open AI账号注册
[ 29M] 12-7 OpenAI 接口测试
[ 49M] 12-8 通过案例演示大模型工作原理
[ 45M] 12-9 [重要]通过案例知晓大模型的使用场景
[ 16M] 12-10 模型演化
[ 28M] 12-11 OpenAI Mode详解
[ 16M] 12-12 模型价格及Token
[ 37M] 12-13 Prompt工程
[ 14M] 12-14 [重要]Chat CompletionAPI及多轮对话的使用
[ 16M] 12-15 [重要]使用ChatGPT助力日常开发的SQL编写
[ 38M] 12-16 Open AI开发者大会发布的新功能
[ 31M] 12-17 Open AI编程老版本
[ 28M] 12-18 Open AI编程新版本
[ 49M] 12-19 Assistants API 编程
13-纠正主观上的错误理解:Spark SQL能带来什么/
[3.8M] 13-1 本章概览
[ 11M] 13-2 为什么要使用SQL
[ 31M] 13-3 官方对Spark SQL的定义
[7.1M] 13-4 [拓展]数据源操作
[8.2M] 13-5 [补充]SQL on Hadoop框架
[ 17M] 13-6 [拓展]Spark SQL的愿景
[ 47M] 13-7 核心概念
[ 42M] 13-8 编程入口点SparkSession
[ 22M] 13-9 spark-shell&spark-sql访问Hive中的表
[ 25M] 13-10 thriftserver&beeline配合使用
[ 25M] 13-11 通过JDBC代码方式访问数据
14-高效快速读写外部数据:Spark SQL外部数据源的使用/
[4.3M] 14-1 本章概览
[ 11M] 14-2 外部数据源的产生背景
[ 60M] 14-3 csv数据源的读操作基本使用
[ 40M] 14-4 csv数据源的读操作进阶使用
[ 30M] 14-5 csv数据源的写操作
[ 34M] 14-6 SaveMode的含义
[ 25M] 14-7 json数据源的读操作基本使用
[ 70M] 14-8 json数据源的读操作进阶使用
[ 22M] 14-9 json数据源的读操作进阶使用
[ 22M] 14-10 json数据源的写操作
[ 21M] 14-11 text数据源的读操作使用
[ 32M] 14-12 text数据源的写操作使用
[ 24M] 14-13 Parquet数据源的读写操作
[ 17M] 14-14 jdbc数据源的读操作使用
[ 16M] 14-15 jdbc数据源的读操作配置化使用
[ 24M] 14-16 jdbc数据源的写操作最佳实践
[ 56M] 14-17 Hive数据源的读写操作最佳实践
[ 31M] 14-18 使用SQL的方式使用外部数据源
[ 54M] 14-19 外部数据源核心类
[ 55M] 14-20 JDBC数据源实现源码分析
[ 35M] 14-21 JDBC数据源实现源码Debug分析
15-快速步入核心编程进阶:DF&DS API编程/
[1.7M] 15-1 本章概览
[ 98M] 15-2 基本API编程
[ 41M] 15-3 基本API编程之分组聚合函数
[ 25M] 15-4 基本API编程之窗口函数
[ 47M] 15-5 RDD与DF的转换操作之反射
[ 21M] 15-6 RDD与DF的转换操作之编程
[ 31M] 15-7 DS操作之RDD转成DS
[ 15M] 15-8 DS操作之DF与DS的互操作
[ 14M] 15-9 扩展之Java类型在API编程中的使用
[ 26M] 15-10 RDD&DF&DS对比
[ 13M] 15-11 自定义外部数据源实战之需求分析
[ 30M] 15-12 自定义外部数据源实战之主体轮廓开发
[ 42M] 15-13 自定义外部数据源实战之开发及测试
16-透过函数进行二次开发:UDF函数在Spark SQL中的使用/
[1.7M] 16-1 本章概览
[6.7M] 16-2 SQL on Hadoop框架中的函数说明
[ 34M] 16-3 UDF函数在API中的使用
[ 16M] 16-4 UDF函数在SQL中的使用
[ 47M] 16-5 UDF函数在Spark SQL中使用的扩展
[ 41M] 16-6 UDAF函数编程主体轮廓开发
[ 68M] 16-7 UDAF函数功能实现及测试
[ 34M] 16-8 UDAF函数新版实现
[1.2M] 16-9 UDTF函数补充说明
17-透过使用知晓执行流程:Spark SQL核心执行流程/
[2.0M] 17-1 课程目录
[ 49M] 17-2 Catalog编程
[ 31M] 17-3 学习源码的方法论
[ 12M] 17-4 通过官方Slide回顾RDD及SparkSQL相关知识
[ 37M] 17-5 通过官方Slide讲解Spark SQL框架的执行流程
[ 42M] 17-6 通过终端运行方式理解Spark SQL框架的执行流程
[ 31M] 17-7 通过代码运行方式理解Spark SQL框架的执行流程
[ 20M] 17-8 新特性之动态分区裁剪引入
[ 21M] 17-9 新特性之动态分区裁剪实现原理
[ 18M] 17-10 新特性之AQE概述
[ 48M] 17-11 新特性之AQE分区自动合并功能详解
[ 30M] 17-12 新特性之AQEJoin策略调整功能详解
[8.0M] 17-13 Spark SQL关于Hints的补充
18-数据开放服务解决方案:为大数据处理成果赋能/
[2.5M] 18-1 课程目录
[ 18M] 18-2 数据服务在大数据平台中的重要地位
[ 21M] 18-3 DBAPI概述
[ 47M] 18-4 DBAPI部署
[6.7M] 18-5 数据源配置
[ 14M] 18-6 API配置
[9.8M] 18-7 客户端设置
[ 13M] 18-8 系统设置及监控
[ 16M] 18-9 作业及总结
19-智能调度系统解决方案:DS在生产上的使用/
[2.0M] 19-1 课程目录
[ 10M] 19-2 调度系统在大数据平台中的重要性
[ 18M] 19-3 初识DS
[ 52M] 19-4 核心名词解释
[ 34M] 19-5 Standalone模式部署
[ 35M] 19-6 工作流的定义及运行实操
[ 12M] 19-7 工作流定时管理
[8.4M] 19-8 数据源中心配置
[ 19M] 19-9 任务类型之shell的使用
[ 13M] 19-10 任务类型之SQL的使用
[ 13M] 19-11 任务类型之HiveCli script的使用
[ 11M] 19-12 任务类型之hivecli file的使用
[ 19M] 19-13 任务类型之Spark3的使用
[ 13M] 19-14 安全中心之租户用户队列
[ 11M] 19-15 安全中心之Worker分组及环境
[ 14M] 19-16 安全中心之告警
20-热门数据湖的技能拓展:基于Spark&Iceberg构建数据湖/
[814K] 20-1 课程目录
[ 20M] 20-2 Iceberg简介
[ 50M] 20-3 Iceberg特性
[ 19M] 20-4 整合Hive准备工作
[ 75M] 20-5 整合Hive结合Catalog创建表详解
[ 47M] 20-6 Iceberg整合Hive的DDL与DML详解
[ 73M] 20-7 Iceberg存储结构
[ 25M] 20-8 整合Spark查询元数据信息
[ 42M] 20-9 整合Spark完成时间线查询及回滚操作
[7.9M] 20-10 动手拓展
21-AI大模型使用进阶:整合SQL在大数据中的使用/
[4.2M] 21-1 课程目录
[ 17M] 21-2 LangChain概述
[ 25M] 21-3 LangChain整合OpenAI和Tongyi模型
[ 47M] 21-4 LangChain整合SQLDatabaseChain完成SQL的处理
[ 35M] 21-5 pyspark-ai
第22章 高手成长路线之挖祖坟:Spark核心源码分析/
[4.7M] 22-1课程目录
[ 31M] 22-2核心概念回顾
[ 59M] 22-3从宏观角度理解作业的执行原理
[ 38M] 22-4foreach算子源码分析
[ 33M] 22-5补充两个Scheduler的初始化
[107M] 22-6DAGScheduler中的runJob方法详解
[ 46M] 22-7handleJobSubmitted方法实现源码分析
[ 57M] 22-8TaskScheduler的submitTask方法源码分析
[ 29M] 22-9task任务执行源码分析
[ 40M] 22-10通过日志输出来学习框架底层的执行流程
[2.7M] 22-11Spark作业执行流程图解
[ 36M] 22-12为什么会产生数据倾斜
[ 57M] 22-13如何定位导致数据倾斜的代码
[ 21M] 22-14数据倾斜解决方案一
[ 12M] 22-15数据倾斜解决方案二
[ 22M] 22-16数据倾斜解决方案三
[ 26M] 22-17数据倾斜解决方案四
[ 18M] 22-18数据倾斜解决方案五
[ 49M] 22-19数据倾斜解决方案六
第23章 智能物业运营系统第四篇:以企业级项目要求实战/
[1.5M] 23-1课程目录
[ 18M] 23-2项目背景描述
[ 30M] 23-3数据流分析
[ 32M] 23-4数据源表结构分析
[ 40M] 23-5停车收入统计结果入表
[ 28M] 23-6停车收入大屏展示
[ 21M] 23-7趋势分析统计结果入表
[2.6M] 23-8趋势分析大屏展示
[ 14M] 23-9放行及抬杠原因次数及占比统计结果入表
[5.2M] 23-10放行及抬杆原因次数及占比分析大屏展示
[ 16M] 23-11区域提杆率统计结果入表
[2.3M] 23-12区域提杆率大屏展示-
[ 21M] 23-13扩展
[ 11M] 23-14课程小结
课件/
第1章 大厂技术首选高薪必备:揭开Spark神秘面纱/
[ 25K] 1-9作业题.pdf
[ 31K] 1-10面试题.pdf
[ 33K] 1-11课外拓展.pdf
第2章 工欲善其事必先利其器:大数据框架环境部署/
[ 26K] 2-13作业题.pdf
第3章 手把手撸个RDD实战:加强基础为Spark预热/
[ 23K] 3-11作业题.pdf
[ 29K] 3-12面试题.pdf
第4章 轻松理解RDD核心本质:结合源码多维度解析/
[ 28K] 4-10作业题.pdf
[ 28K] 4-11面试题.pdf
第5章 快速步入核心编程基础:RDD转换与动作编程/
[ 35K] 5-45作业题.pdf
[ 35K] 5-46面试题.pdf
第6章 智能物业运营系统第一篇:地理位置的解析实战/
[ 38K] 6-21作业题.pdf
[ 34K] 6-22面试题.pdf
第7章 深入理解核心必备进阶:分区器依赖缓存策略/
[ 29K] 7-14作业题.pdf
[ 29K] 7-15面试题.pdf
第8章 架构知其然知其所以然:术语&运行架构&on YARN/
[ 26K] 8-14作业题.pdf
[ 27K] 8-15面试题.pdf
第9章 智能物业运营系统第二篇:大数据应用监控及告警/
[ 28K] 9-14作业题.pdf
[ 29K] 9-15面试题.pdf
第10章 高手成长路线之学调优:RDD各种姿势的调优/
[ 33K] 10-18作业题.pdf
[ 38K] 10-19面试题.pdf
第11章 智能物业运营系统第三篇:业务数据采集及累计问题/
[ 55K] 11-18作业题.pdf
[ 39K] 11-19面试题.pdf
第12章 最热门的AI大模型入门:ChatGPT为工作插上翅膀/
第13章 纠正主观上的错误理解:Spark SQL能带来什么/
[ 30K] 13-12作业题.pdf
[ 28K] 13-13面试题.pdf
第14章 高效快速读写外部数据:Spark SQL外部数据源的使用/
[ 30K] 14-22作业题.pdf
[ 35K] 14-23面试题.pdf
第15章 快速步入核心编程进阶:DF&DS API编程/
[ 36K] 15-14作业题.pdf
第16章 透过函数进行二次开发:UDF函数在Spark SQL中的使用/
[ 31K] 16-10作业题.pdf
[ 30K] 16-11面试题.pdf
第17章 透过使用知晓执行流程:Spark SQL核心执行流程/
[ 40K] 17-14作业题.pdf
[ 32K] 17-15面试题.pdf
第18章 数据开放服务解决方案:为大数据处理成果赋能/
[ 33K] 18-10作业题.pdf
代码/





评论0