

课程介绍
大数据工程师2024视频教程,由it资源网整理发布。本课是一套零基础系统进阶的体系化课程,课程累计处理TB级数据,数据处理能力支持PB级数据,达到主流一线公司水准,整合电商、直播、搜索、中台4大“可写入简历的”企业级项目,实战上手加深理解。
相关推荐
极客时间 – 大数据训练营
大数据硬核技能进阶:Spark3实战智能物业运营系统
项目驱动式学习,知其然更知其所以然,从入门到入职,从基础到应用,最后达到中级大数据开发岗位能力标准

课程实战项目
离线数据仓库:整合各个业务线数据,为各个业务系统提供统一&规范的数据出口。是整个大数据系统中的关键,是所有数据分析、数据挖掘等工作的基础。
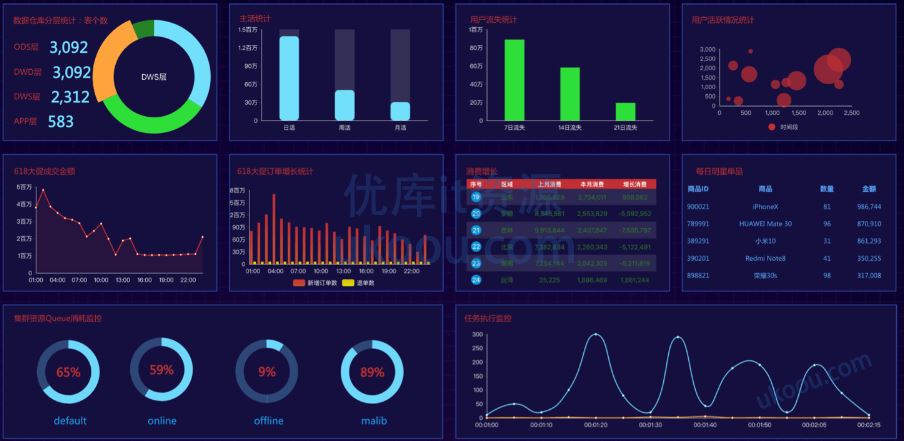
实时数据仓库大屏:引入Flink CDC和数据湖实现湖仓一体(批流一体)架构,解决常规实时数据仓库存在的一些问题。
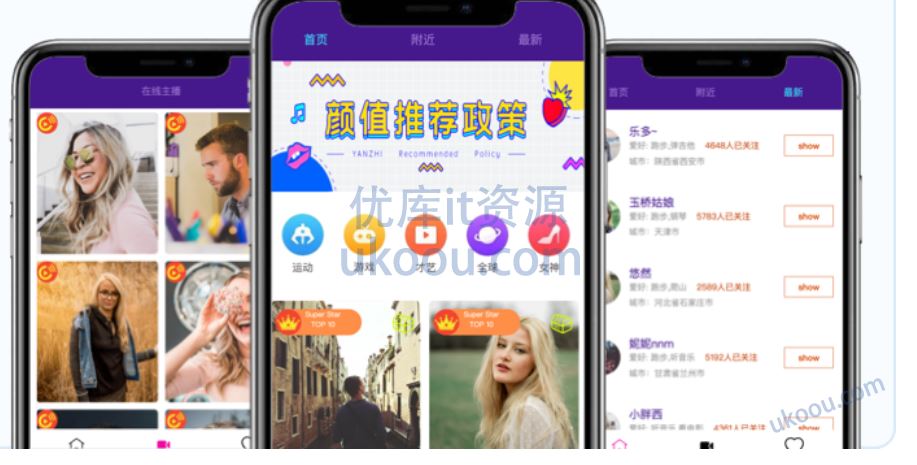
直播平台三度关系推荐:构建直播平台用户三度关系推荐功能,增加用户互动/主播曝光量/提升平台用户活跃度。详细分析数据采集/数据分发/数据存储/数据计算/数据展现等功能,完整复现互联网企业大数据项目从0~1,从1~N的开发过程。
开发仿百度搜索引擎:实现仿百度搜索引擎的海量数据存储和检索功能,可以提供海量数据下的多条件快速复杂检索能力。
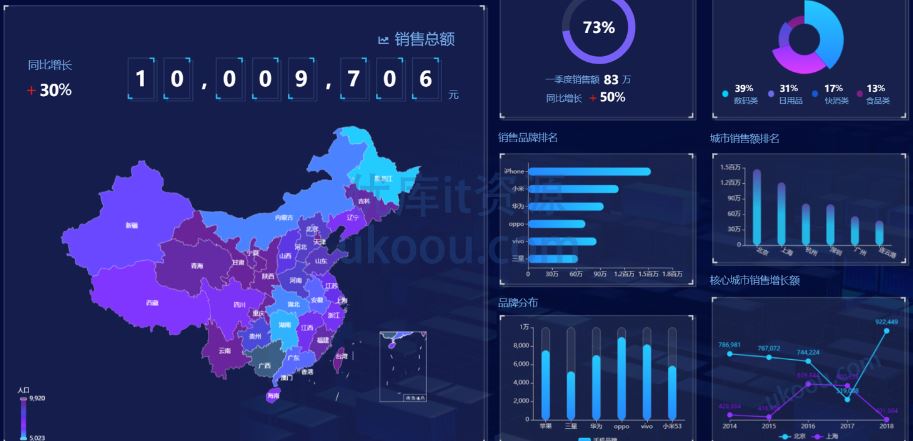
数据中台大屏:打通数据孤岛,构建企业级数据中台,赋能企业数字化转型发展。数据中台从后台将数据流入,完成海量数据的存储、计
算、服务化,构成企业的核心数据能力,为前台基于数据的定制化创新和业务中台基于数据反馈的持续演进提供了强大支撑。开发数据中台之数据加工总线组件。
资源目录
阶段一:走进大数据/
1-学好大数据先攻克Linux/
第1章 笑傲大数据成长体系课[必看]/
第2章 Linux虚拟机安装配置/
第3章 Linux极速上手/
第4章 Linux试炼之配置与shell实战/
第5章 Linux总结与走进大数据/
2-大数据起源之初识Hadoop/
第1章 初识Hadoop/
第2章 Hadoop的两种安装方式/
3-Hadoop之HDFS的使用/
第1章 HDFS介绍/
第2章 HDFS基础操作/
第3章 Java操作HDFS/
4-Hadoop之HDFS核心进程剖析/
第1章 初识NameNode/
第2章 NameNode进阶/
第3章 HDFS高级/
第4章 [扩展内容]HDFS写数据源码剖析/
5-Hadoop之初识MR/
第1章 初识MapReduce/
第2章 实战:WordCount/
第3章 深入MapReduce/
第4章 精讲Shuffle执行过程及源码分析输入输出/
阶段二:PB级离线数据计算分析存储方案/
1-拿来就用的企业级解决方案/
第1章 剖析小文件问题与企业级解决方案/
第2章 剖析数据倾斜问题与企业级解决方案/
第3章 YARN实战/
第4章 Hadoop官方文档使用指北[授人以鱼不如授人以渔]/
第5章 Hadoop核心复盘/
第6章 [福利加油站]/
2-Flume从0到高手一站式养成记/
第1章 极速入门Flume/
第2章 极速上手Flume使用/
第3章 精讲Flume高级组件/
第4章 Flume出神入化篇/
第5章 Flume核心复盘/
3-数据仓库Hive从入门到小牛/
第1章 快速了解Hive/
第2章 数据库与数据仓库区别/
第3章 Hive基础使用/
第4章 Hive核心实战/
第5章 Hive高级函数实战/
第6章 Hive技巧与核心复盘/
4-Hive扩展内容/
第1章 常见数据压缩格式的使用/
第2章 常见数据存储格式的使用/
5-快速上手NoSQL数据库HBase/
第1章 快速了解HBase/
第2章 快速上手使用HBase/
第3章 深入HBase架构原理/
第4章 HBase高级用法/
第5章 HBase调优策略和扩展内容/
6-数据分析引擎之Impala/
第1章 快速了解Impala/
第2章 快速上手使用Impala/
第3章 Impala高级内容/
阶段三:Spark+综合项目:电商数据仓库设计与实战/
1-7天极速掌握Scala语言/
第1章 Scala极速入门/
[认准一手完整 www.ukoou.com]
第2章 Scala基础语法/
第3章 Scala面向对象/
第4章 Scala函数式编程/
第5章 Scala高级特性/
第6章 Scala核心复盘/
2-Spark快速上手/
第1章 初识Spark/
第2章 解读Spark工作与架构原理/
第3章 Spark实战:单词统计/
第4章 Transformation与Action开发实战/
第5章 RDD持久化/
第6章 TopN主播统计/
第7章 面试与核心复盘/
3-Spark性能优化的道与术/
第1章 Spark三种任务提交模式/
第2章 Shuffle机制分析/
第3章 Spark之checkpoint/
第4章 Spark程序性能优化企业级最佳实践/
第5章 Spark性能优化之算子优化/
第6章 极速上手SparkSql/
第7章 Spark实战与核心复盘/
4-Spark3.x扩展内容/
第1章 快速上手使用Spark 3.x/
第2章 Spark 3.x版本中新特性的原理及应用/
第3章 SparkSQL 集成 Hive/
5-综合项目:电商数据仓库之用户行为数仓/
第1章 电商数据仓库效果展示/
第2章 数据仓库前置技术/
第3章 电商数仓技术选型/
第4章 数据生成与采集/
第5章 用户行为数仓设计与实现/
第6章 项目核心复盘/
6-综合项目:电商数据仓库之商品订单数仓/
第1章 商品订单数仓需求分析/
@it资源网ukoou.com
第2章 需求设计与实现/
第3章 订单拉链表实战/
第4章 数据可视化和任务调度实现/
第5章 项目核心复盘/
第6章 数据压缩格式和存储格式在数仓中的应用/
阶段四:高频实时数据处理+海量数据全文检索方案/
1-消息队列之Kafka从入门到小牛/
第1章 初识Kafka/
第2章 Kafka集群安装部署/
第3章 Kafka使用初体验/
第4章 Kafka核心扩展内容/
第5章 Kafka核心之存储和容错机制/
第6章 Kafka生产消费者实战/
第7章 Kafka技巧篇/
第8章 Kafka小试牛刀实战篇/
第9章 Kafka核心复盘/
2-极速上手内存数据库Redis/
[认准一手完整 www.ukoou.com]
第1章 快速了解Redis/
第2章 Redis核心实践/
第3章 Redis封装工具类技巧/
第4章 Redis高级特性/
第5章 Redis核心复盘/
3-Flink快速上手篇/
第1章 初识Flink/
第2章 实战:流处理和批处理程序开发/
第3章 Flink集群安装部署/
第4章 Flink核心API之DataStream API/
第5章 Flink核心API之DataSet API/
第6章 Flink核心API之Table API和SQL/
第7章 Flink核心复盘/
4-Flink高级进阶之路/
第1章 Flink中的Window和Time详解/
第2章 Flink中的Watermark深入剖析/
第3章 Flink中的并行度详解/
第4章 Flink之Kafka Connector专题/
第5章 SparkStreaming快速上手/
第6章 Flink核心复盘/
第7章 [福利加油站]/
5-Flink1.15新特性及状态的使用/
第1章 Flink新版本新特性介绍/
第2章 快速上手使用Flink 1.15/
第3章 State(状态)的使用与管理/
6-Flink1.15之状态的容错与一致性/
第1章 State(状态)的容错与一致性/
第2章 Checkpoint与State底层原理深度剖析/
第3章 Kafka-connector新API的使用/
7-FlinkSQL(1.15)快速上手/
第1章 Flink SQL快速理解/
第2章 Flink SQL中的表类型详解/
第3章 Flink SQL常见的数据类型/
第4章 Flink SQL中的列类型详解/
第5章 Flink SQL中的DML语句详解/
第6章 Flink SQL中的Catalog/
第7章 Flink SQL如何兼容Hive/
第8章 Flink SQL Client客户端工具/
8-FlinkSQL双流JOIN详解/
第1章 Flink SQL双流 Join概述/
第2章 Flink SQL双流 Join之普通Join/
第3章 Flink SQL双流 Join之时间区间Join/
第4章 Flink SQL双流 Join之快照Join/
第5章 Flink SQL双流 Join之维表Join/
第6章 Flink SQL双流 Join之数组炸裂/
第7章 Flink SQL双流 Join之表函数Join/
第8章 Flink SQL双流 Join之窗口 Join/
第9章 Flink SQL 双流JOIN总结/
第10章 Flink SQL扩展内容/
9-实时OLAP引擎之ClickHouse/
第1章 OLAP数据分析引擎整体概述/
第2章 快速了解ClickHouse/
第3章 快速上手使用ClickHouse/
第4章 ClickHouse核心内容/
第5章 ClickHouse分布式集群/
第6章 ClickHouse数据查询/
10-全文检索引擎Elasticsearch/
第1章 快速了解Elasticsearch/
第2章 快速上手使用Elasticsearch/
第3章 Elasticsearch分词详解/
第4章 Elasticsearch查询详解/
第5章 Elasticsearch的高级特性/
11-Es+HBase仿百度搜索引擎项目/
第1章 企业中快速复杂查询痛点分析/
第2章 仿百度搜索引擎项目架构设计/
第3章 ES高级特性扩展/
第4章 开发仿百度搜索引擎项目/
第5章 项目中遇到的典型问题/
阶段五:综合项目:三度关系推荐系统+数据中台/
1-实时数仓-Kafka Eagle+DS/
第1章 Kafka Eagle快速理解/
第2章 Kafka Eagle常见功能的使用/
第3章 DolphinScheduler快速理解/
第4章 DolphinScheduler常见功能介绍/
第5章 DolphinScheduler案例实战/
2-实时数仓-Flink CDC数据采集/
第1章 Flink CDC快速理解/
第2章 Flink CDC之MySQL CDC/
第3章 MySQL CDC支持的高级特性/
第4章 MySQL CDC扩展内容/
3-实时数仓-Paimon(数据湖)快速上手/
第1章 Paimon快速理解/
第2章 快速上手使用Paimon/
第3章 Paimon中的表类型-全局维度/
第4章 Paimon中的表类型-存储维度/
4-实时数仓-Paimon(数据湖)高级进阶/
第1章 Paimon的核心操作/
第2章 CDC数据摄取/
第3章 Hive引擎集成Paimon/
第4章 Paimon底层存储文件深入剖析/
第5章 Paimon性能优化和管理维护/
5-直播平台三度关系推荐V1.0/
第1章 项目介绍及演示/
第2章 项目技术选型/
第3章 Neo4j图数据库快速上手使用/
第4章 数据采集模块分析/
第5章 数据采集+聚合+分发+落盘/
第6章 数据计算核心指标分析/
第7章 数据核心指标计算/
第8章 项目核心复盘/
6-直播平台三度关系推荐V2.0/
第1章 V1.0架构方案分析及V2.0架构设计/
第2章 V2.0架构之数据核心指标计算/
第3章 数据接口定义及开发/
第4章 数据展示/
第5章 项目扩展优化/
第6章 项目核心复盘/
7-数据中台大屏/
第1章 数据中台的前世今生/
第2章 数据中台架构/
第3章 什么样的企业适合建设数据中台/
第4章 数据中台企业级解决方案/
第5章 项目总结/
第6章 数据中台之数据加工总线/
第7章 数据加工总线之SparkSQL计算引擎开发/
第8章 数据加工总线之FlinkSQL计算引擎开发/
第9章 后期展望/
资料代码/
电子书/
资源目录截图






评论0